Neal Ford 在《函数式编程思想》(Functional Thinking)中提到面向对象编程是通过封装可变因素控制复杂性(makes code understandable),而函数式编程是通过消除可变因素控制复杂性的。
封装和消除,哪种好理解?
封装是为了构造抽象屏障(Abstract Barrier),到达隐藏信息的目的。任何编程范式都不会缺少封装,因为这是人类简化理解事物的方式。只不过在面向对象编程语言中,封装、继承和多态(polymorphism)被拔到了一种必须充分理解的高度,而 Bob 在函数式设计中挑明了态度,他认为多态比其他两者高出一筹。原因在于进行高层次策略设计时,多态是调整依赖关系行之有效的方法。我认为他说得有一定道理,但是弱化封装这个性质倒和他的中心思想相背离,因为在这本书里,面向对象的封装和函数式的消除是棋逢对手的关键性质,费点笔墨解释清楚,很有必要。
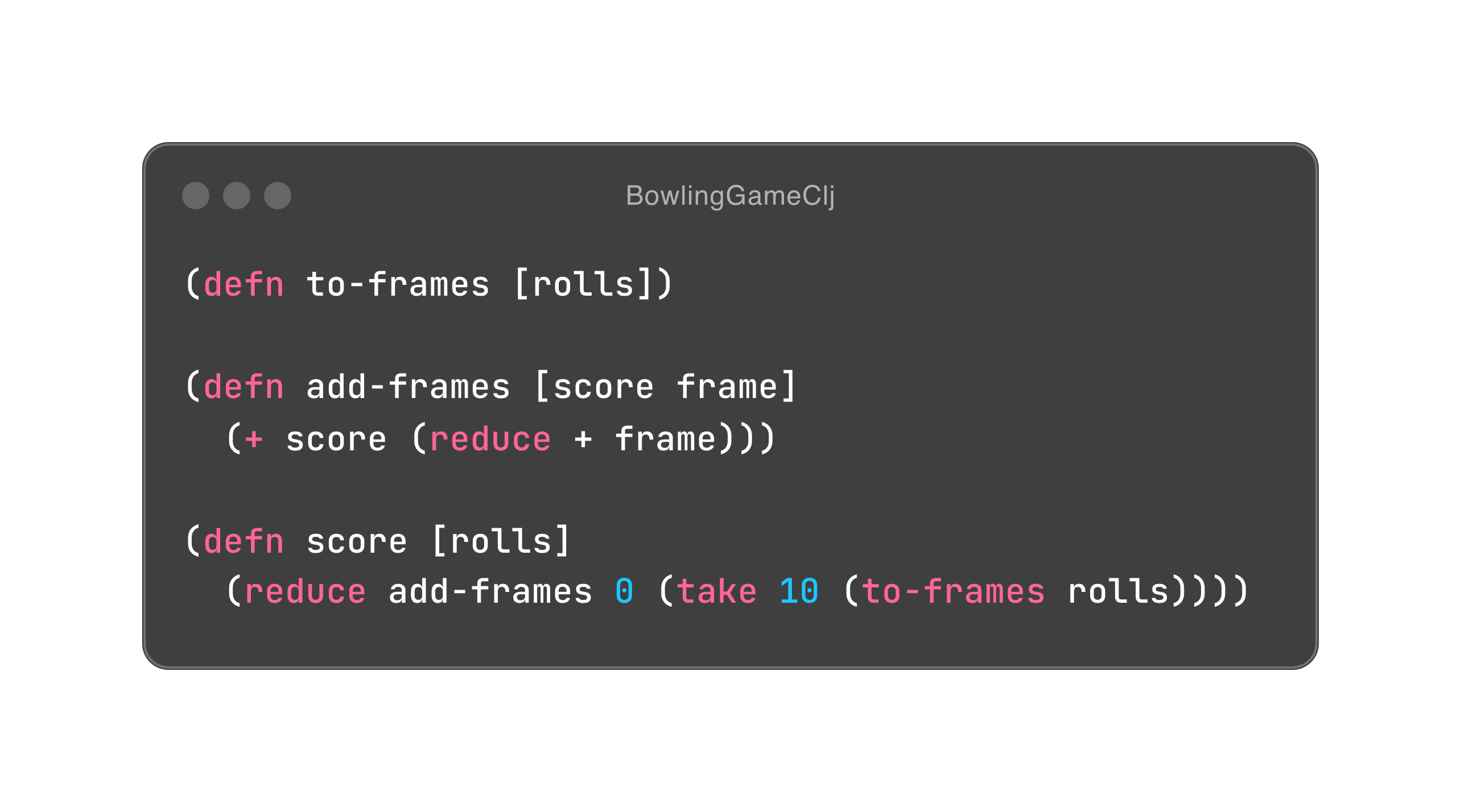
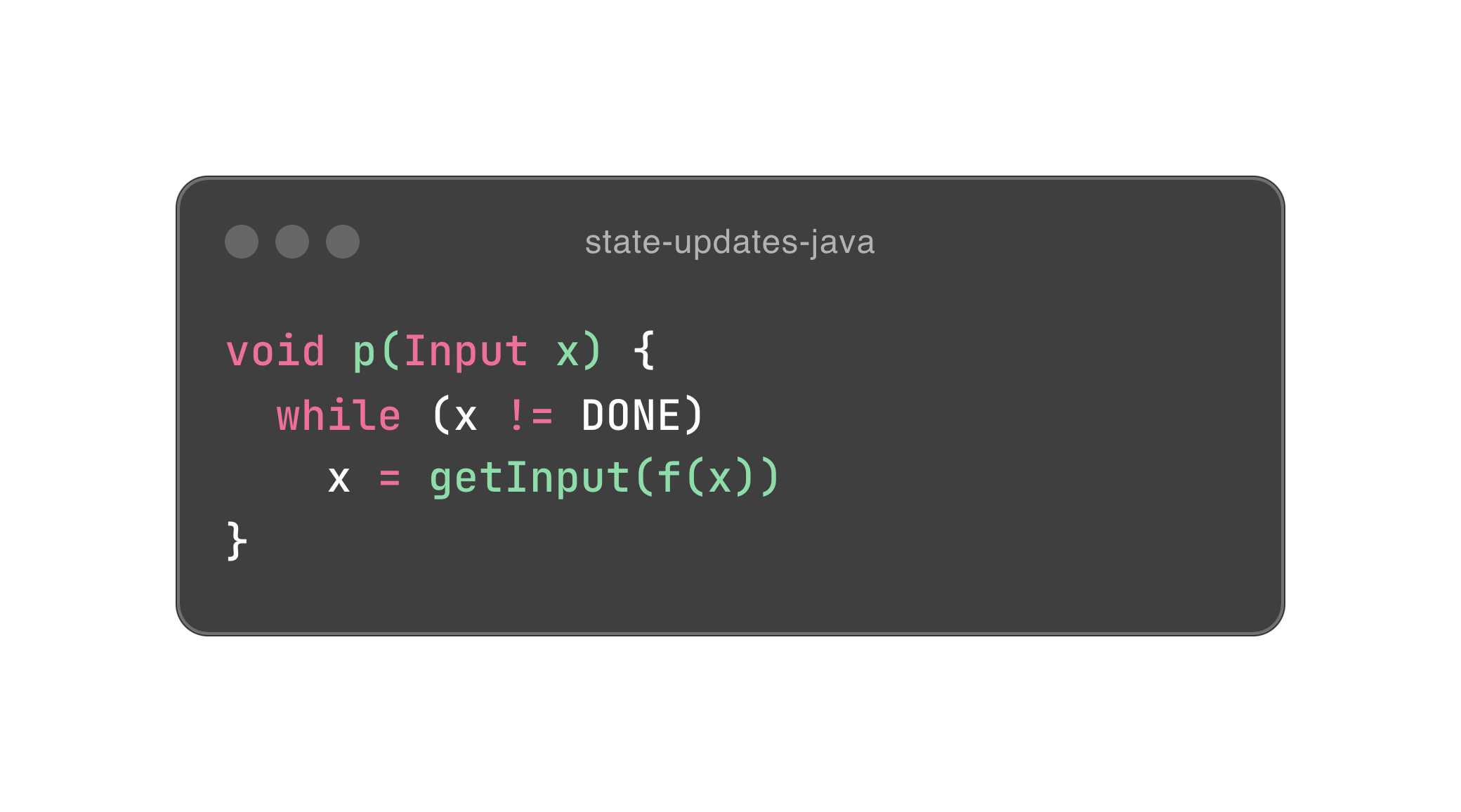
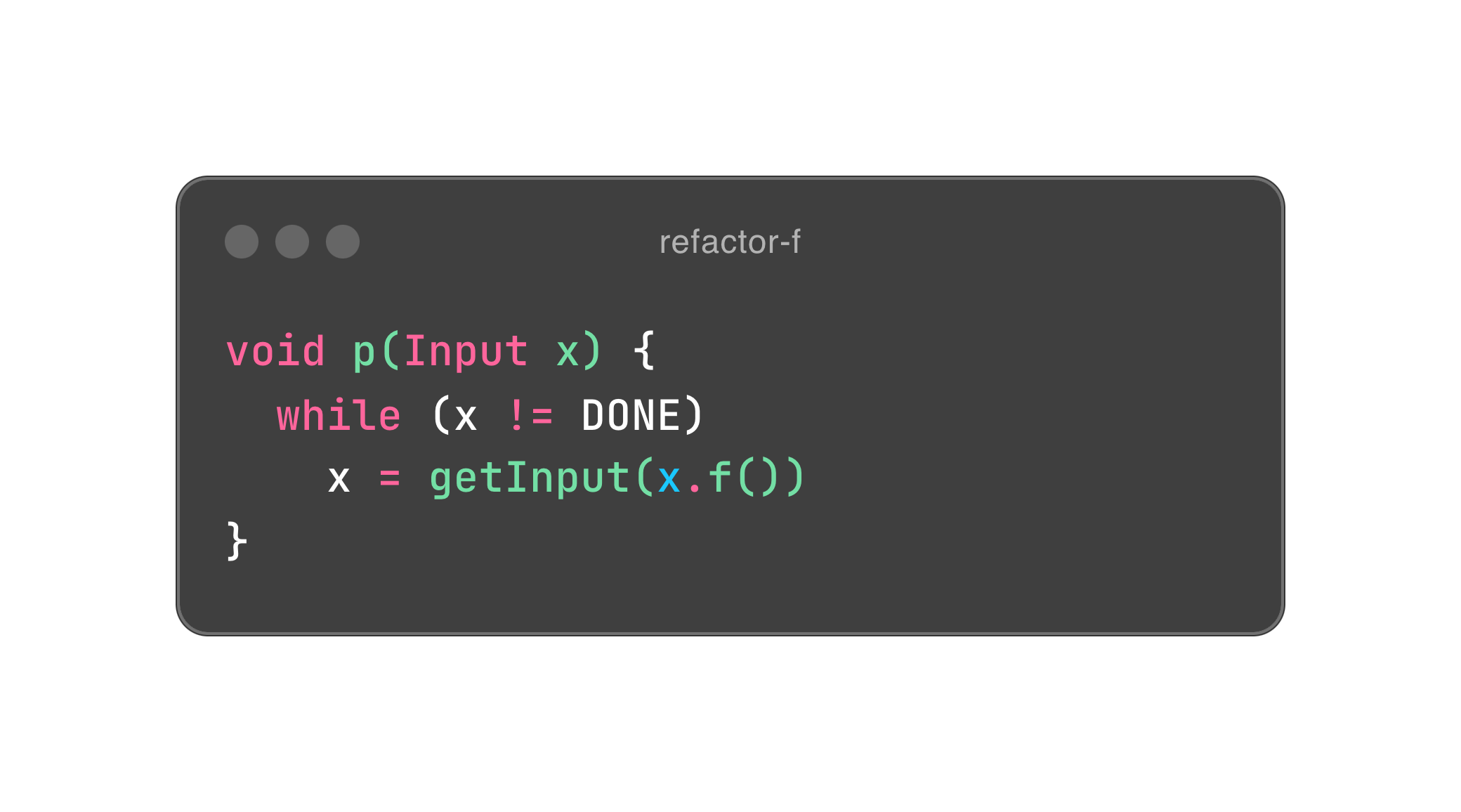
Bob 大叔在第五章里列举了两段伪代码,如下。
{:height 442, :width 780}
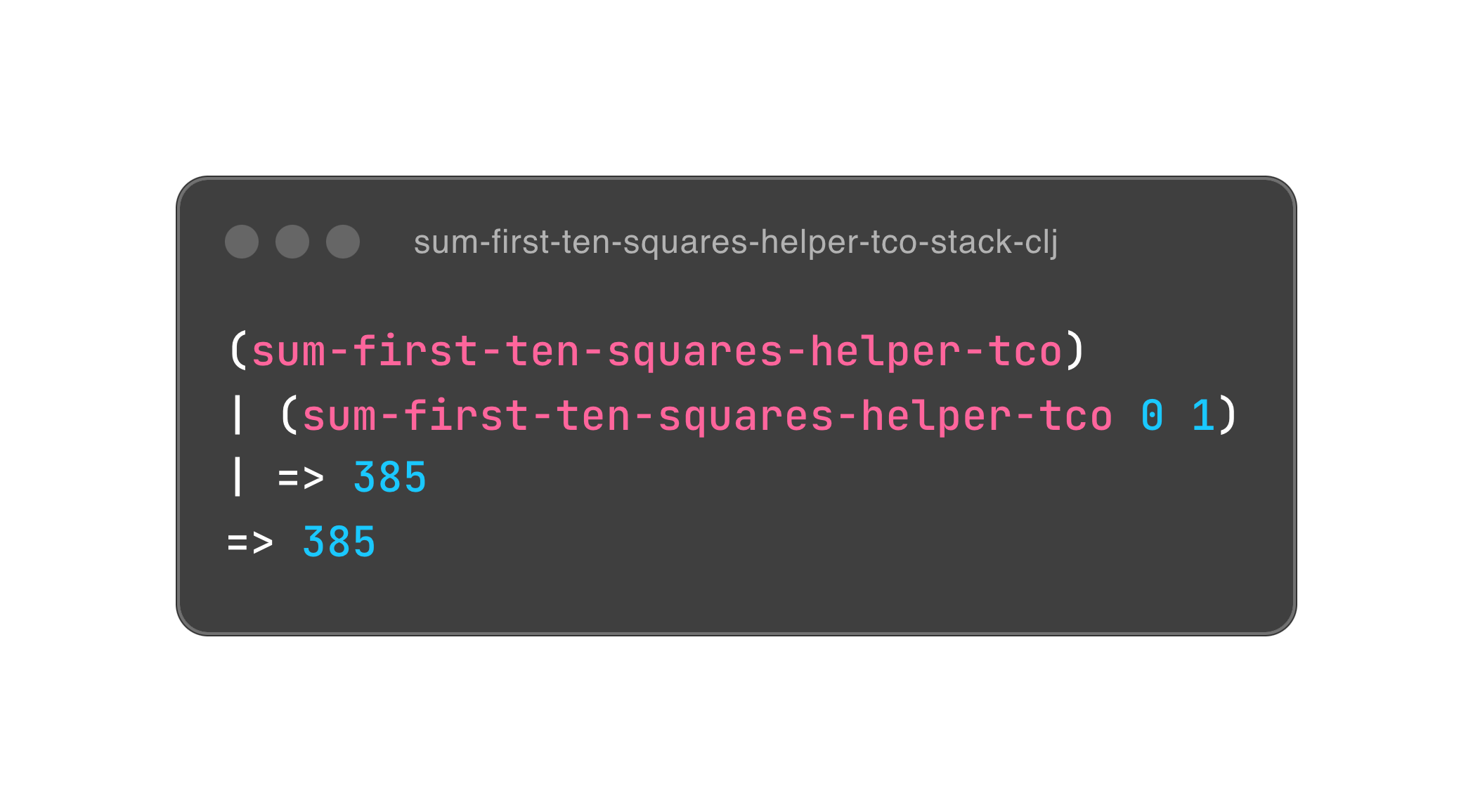
如果你看过我之前写的文章,不难理解这里发生了什么,无非用尾递归消除了 x 的赋值。在 Bob 大叔的眼中,赋值等同于可变性。所以,函数式设计的精髓就是消除可变性。
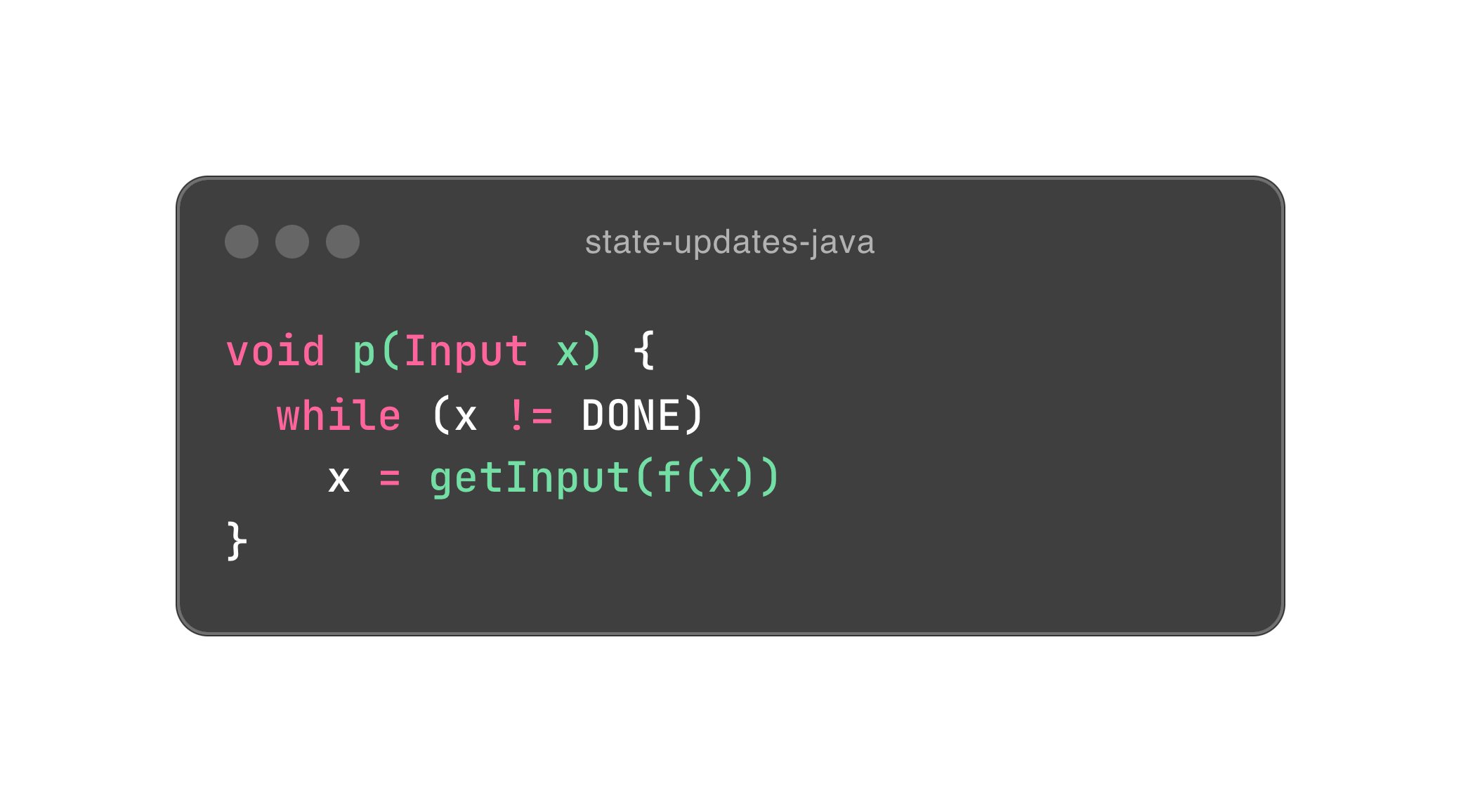
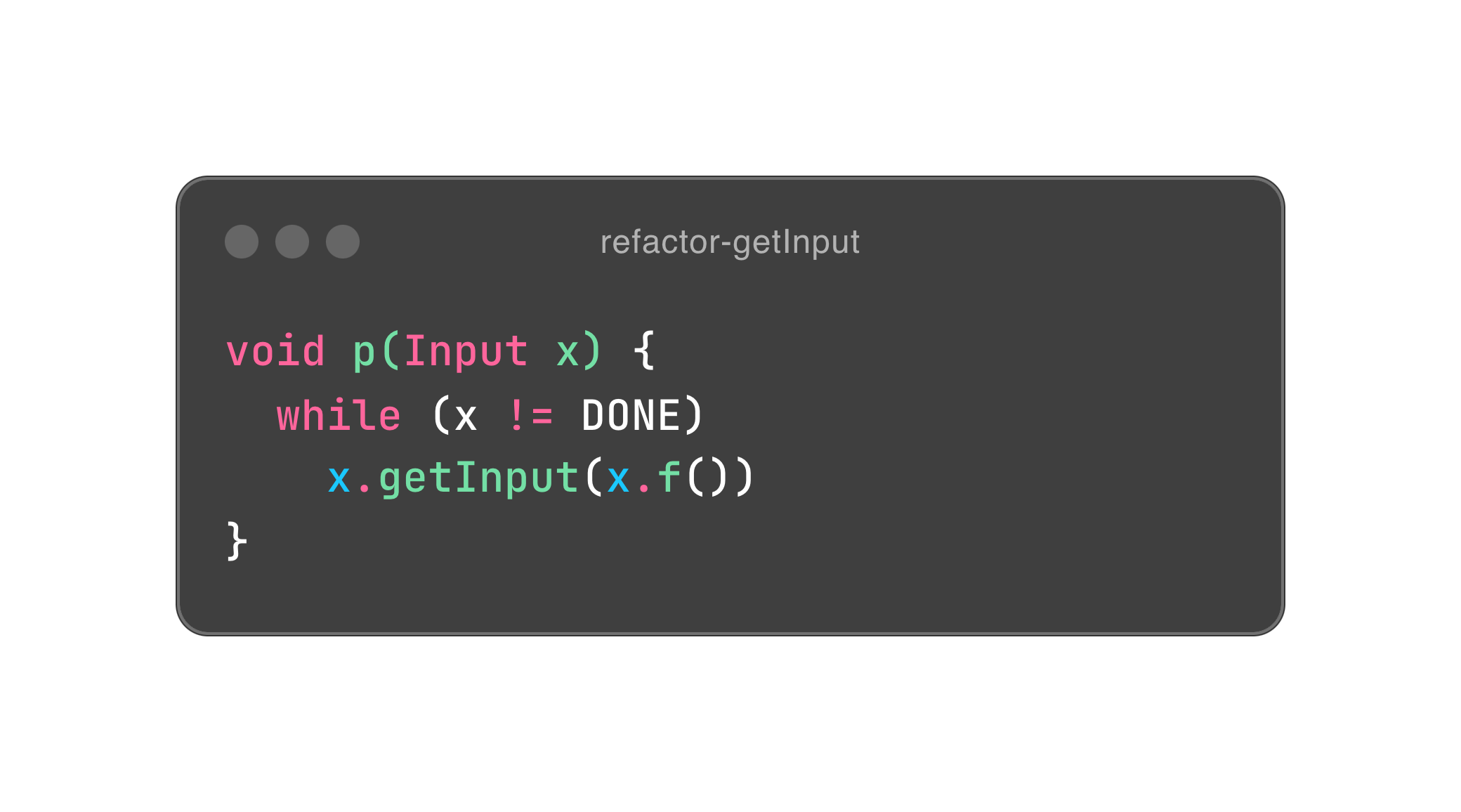
可是,除了赋值,第一段程序跟封装有什么关系呢?别急,我们稍微重构一下它。
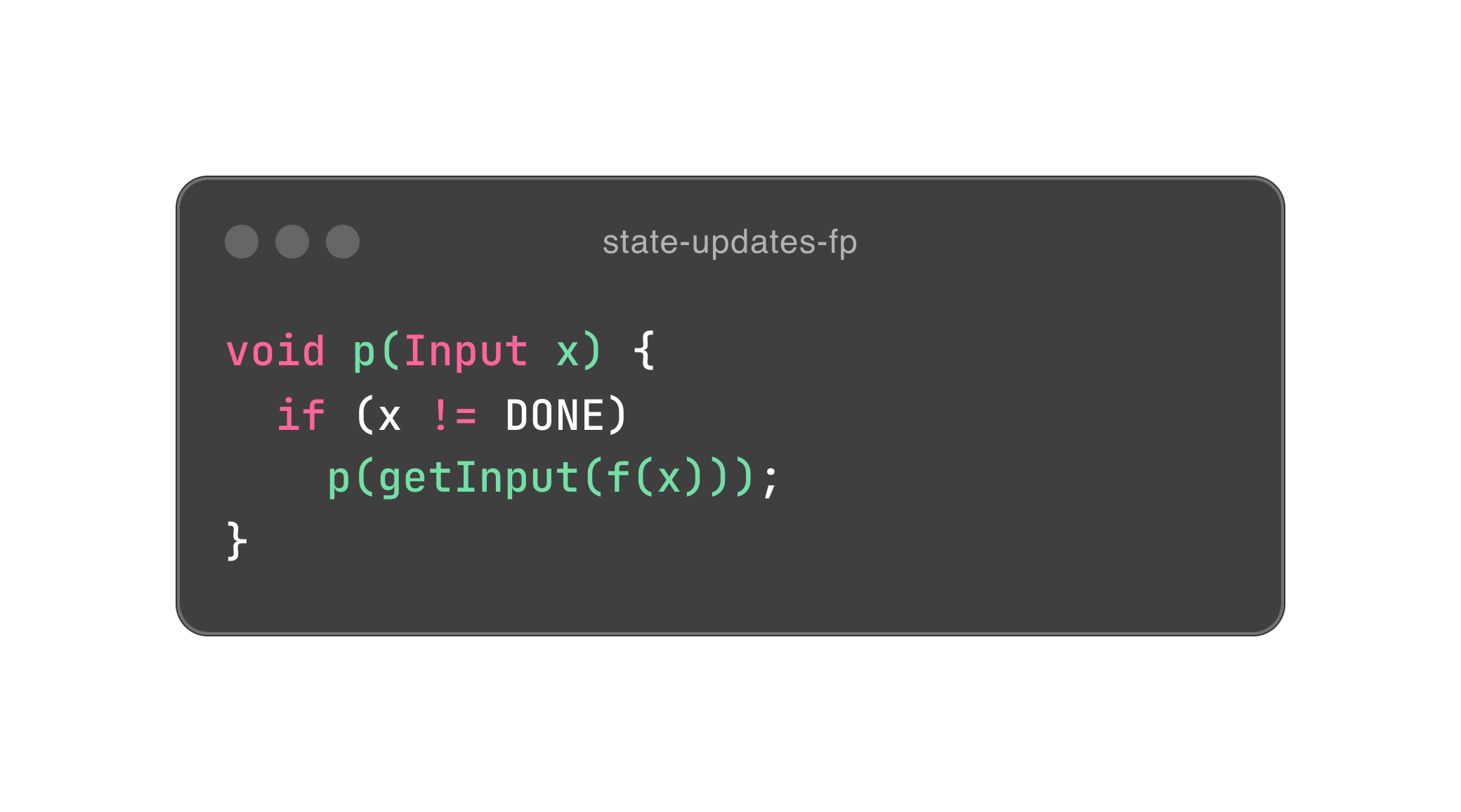
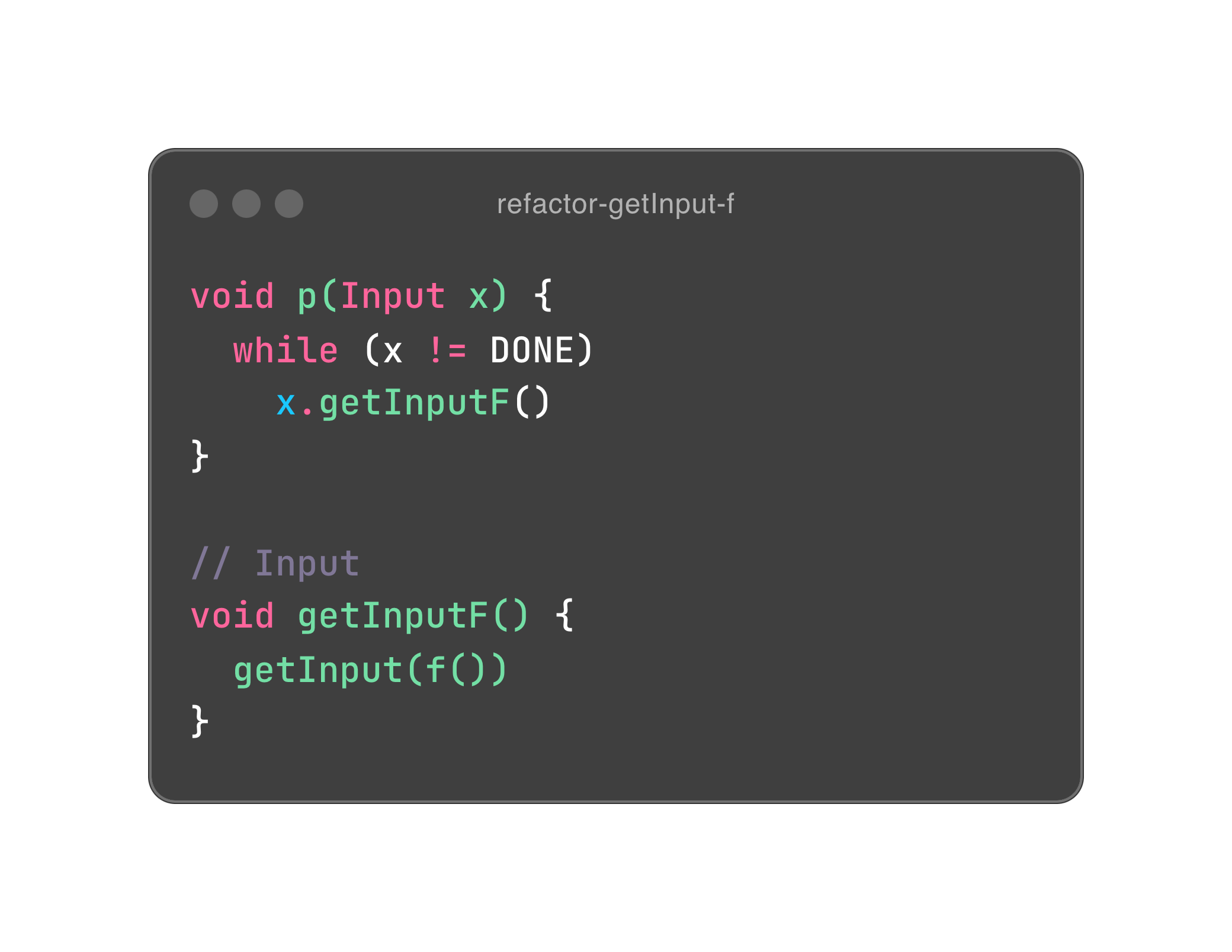
Input x 是一个对象,所以我们就把所有依赖其本身的行为通通封装进它的体内,希望你能感受到封装的力量。这里面有一点洞察,面向对象尽量会把行为放进对象体内,以符合数据内聚性的需要。也因此,对象的状态会原地改变,相当于赋值。
Bob 大叔成名已久,是面向对象编程领域当之无愧的领军人物。如今,他出一本函数式编程的书籍,我想他的多数读者应该会感到疑惑:没想到你浓眉大眼的,居然也叛变了“革命”。Bob 大叔叛变了吗?他的这本书和他之前的诸多作品文脉想通,有继承也有创新,落脚点还是实用。我用电梯演讲的方式概括了这本书的内容和优势。 对于:Bob 大叔的读者多数是面向对象编程的熟练手
一问三连,一发入魂
决定读不读一本书,最好的方式是带着疑问去检索答案。我拿到这本书,脑子中闪现的一个问题就是函数式设计是作为面向对象设计的对立面提出来的吗?当我翻开前面几页,发现 Bob 大叔居然用了 Clojure 这门 Lisp 的方言来阐述观点,不由得心头一紧,这门编程语言受众很窄,恐怕会劝退很多读者呀!写过如此之多畅销书的 Bob 大叔不会没有意识到这点,那他的目的何在?我把书从头粗粗地翻到末尾,闭目凝神,回想 2010 至 2020 年这十年间函数式编程语言红极一时又式微的过程,叠加 genAI Copilot 辅助编程的滔天巨浪,不免心有戚戚,喟然叹曰:现在再来讨论编程范式,有用吗?
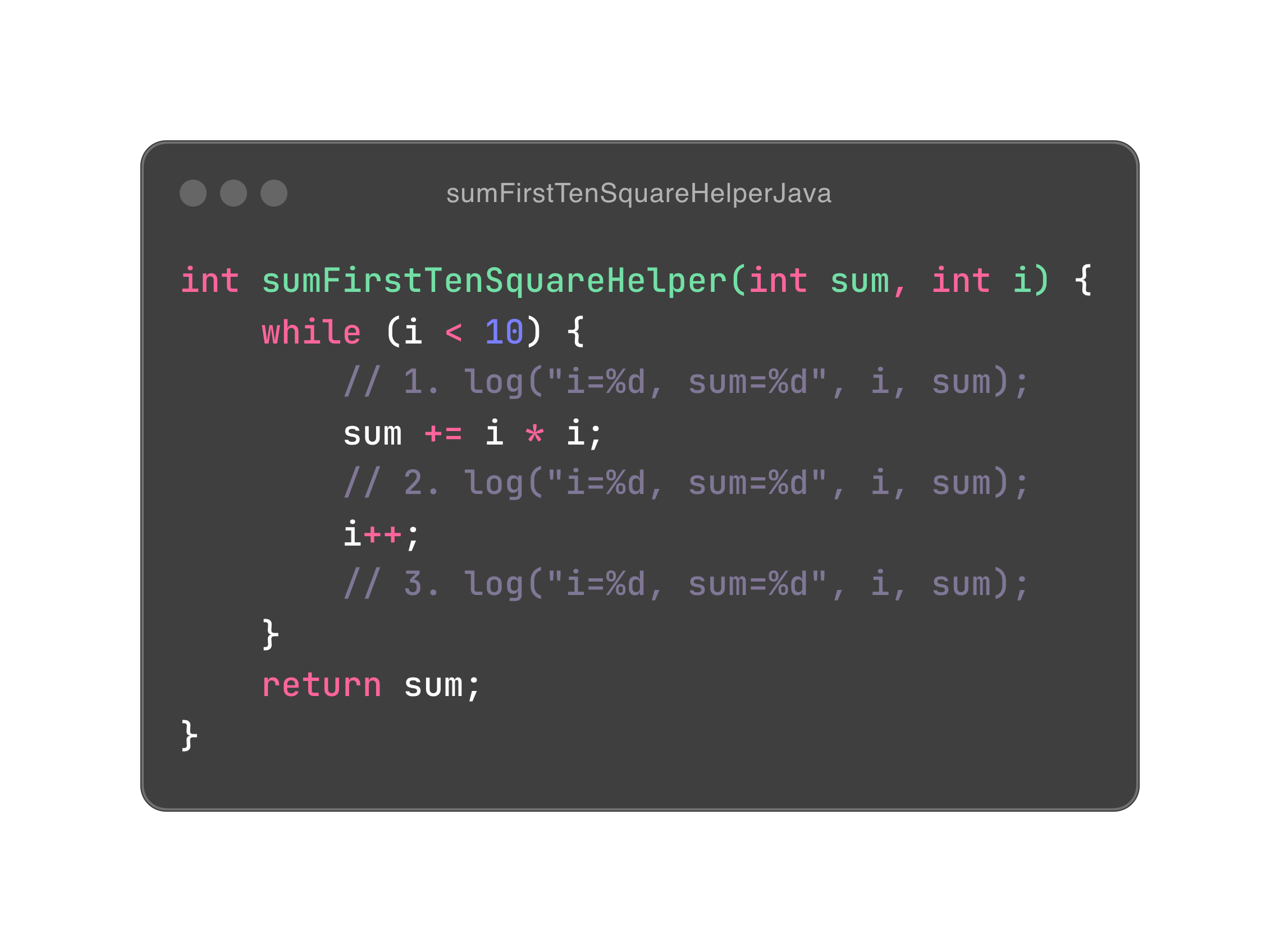
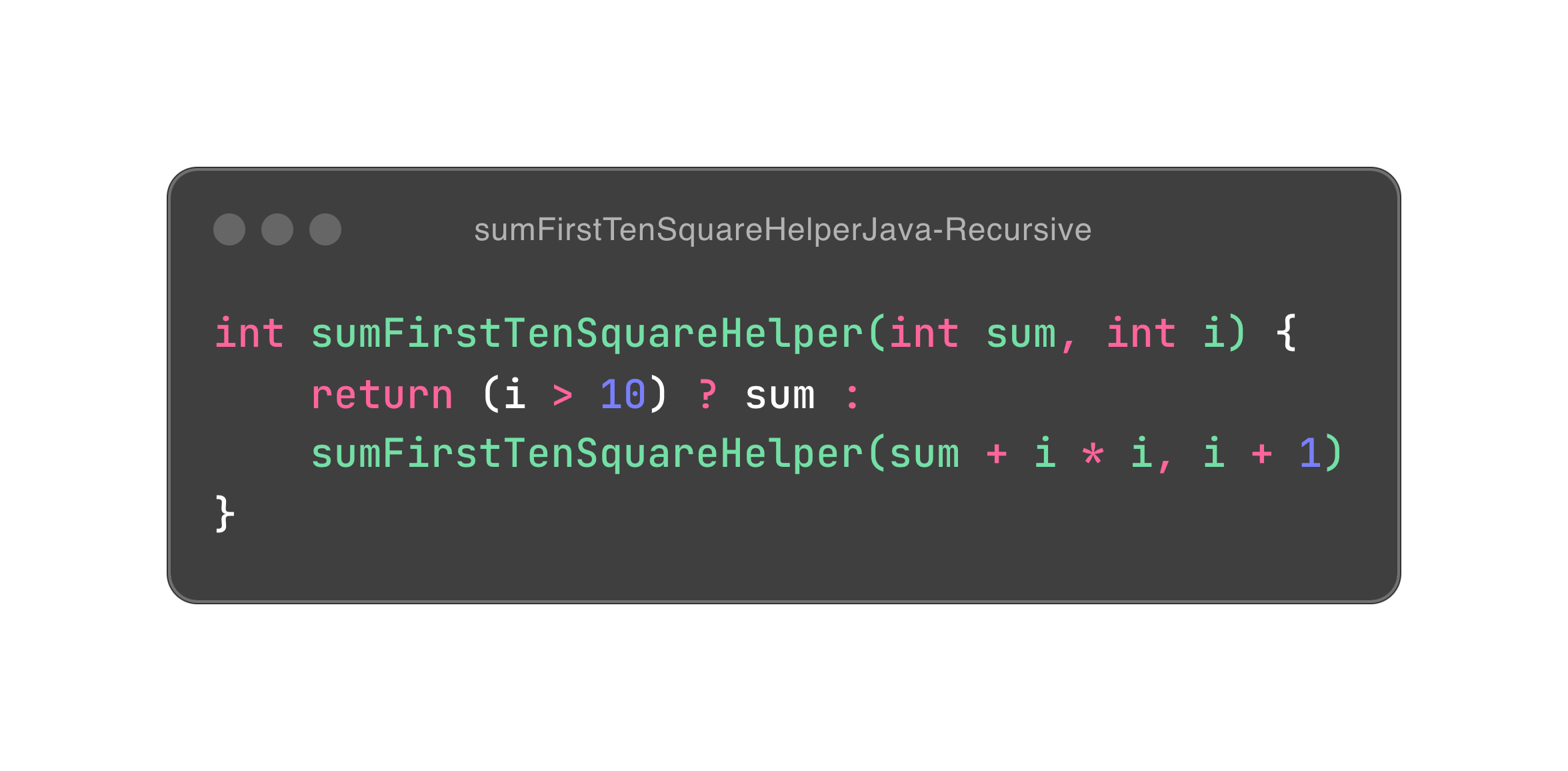
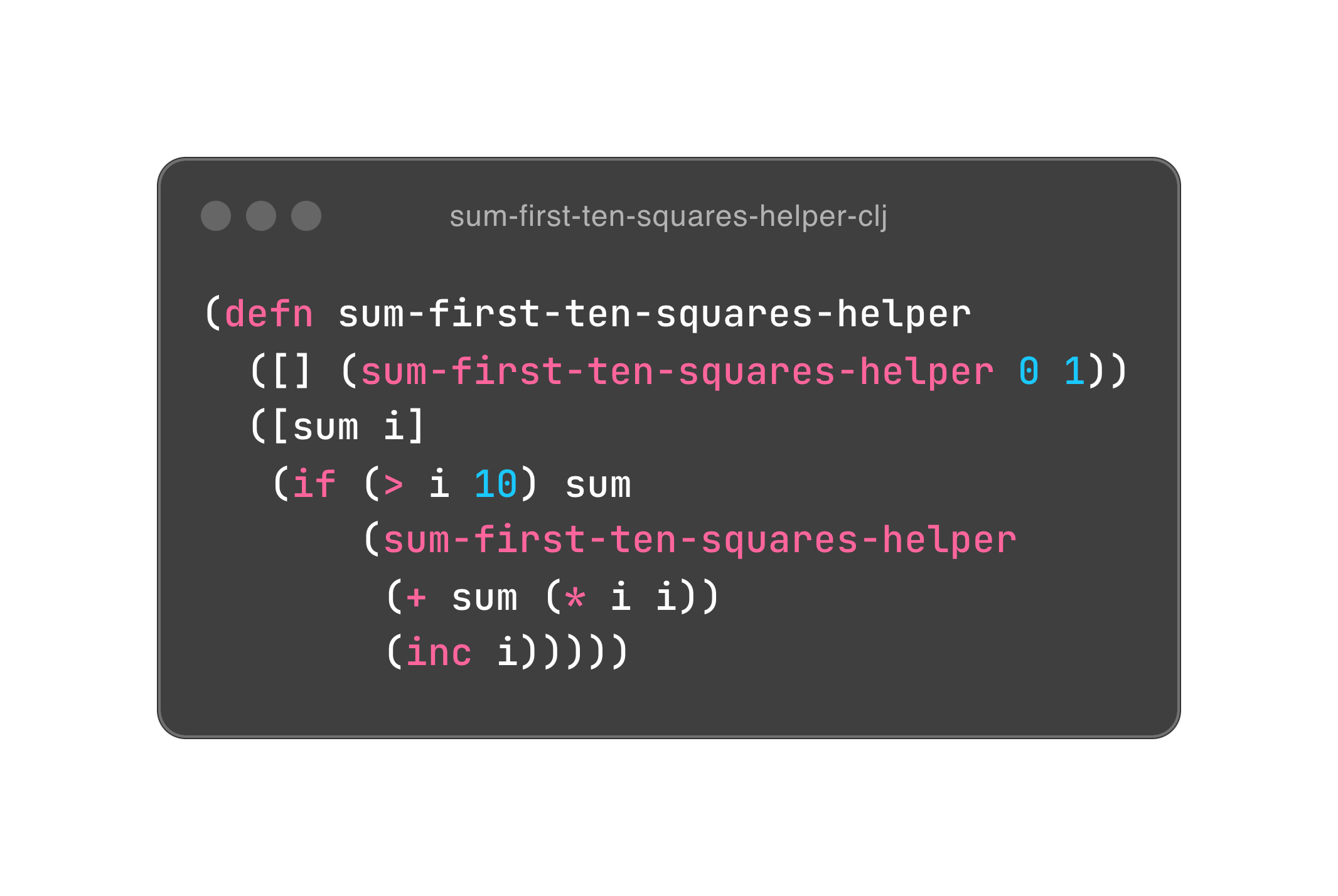
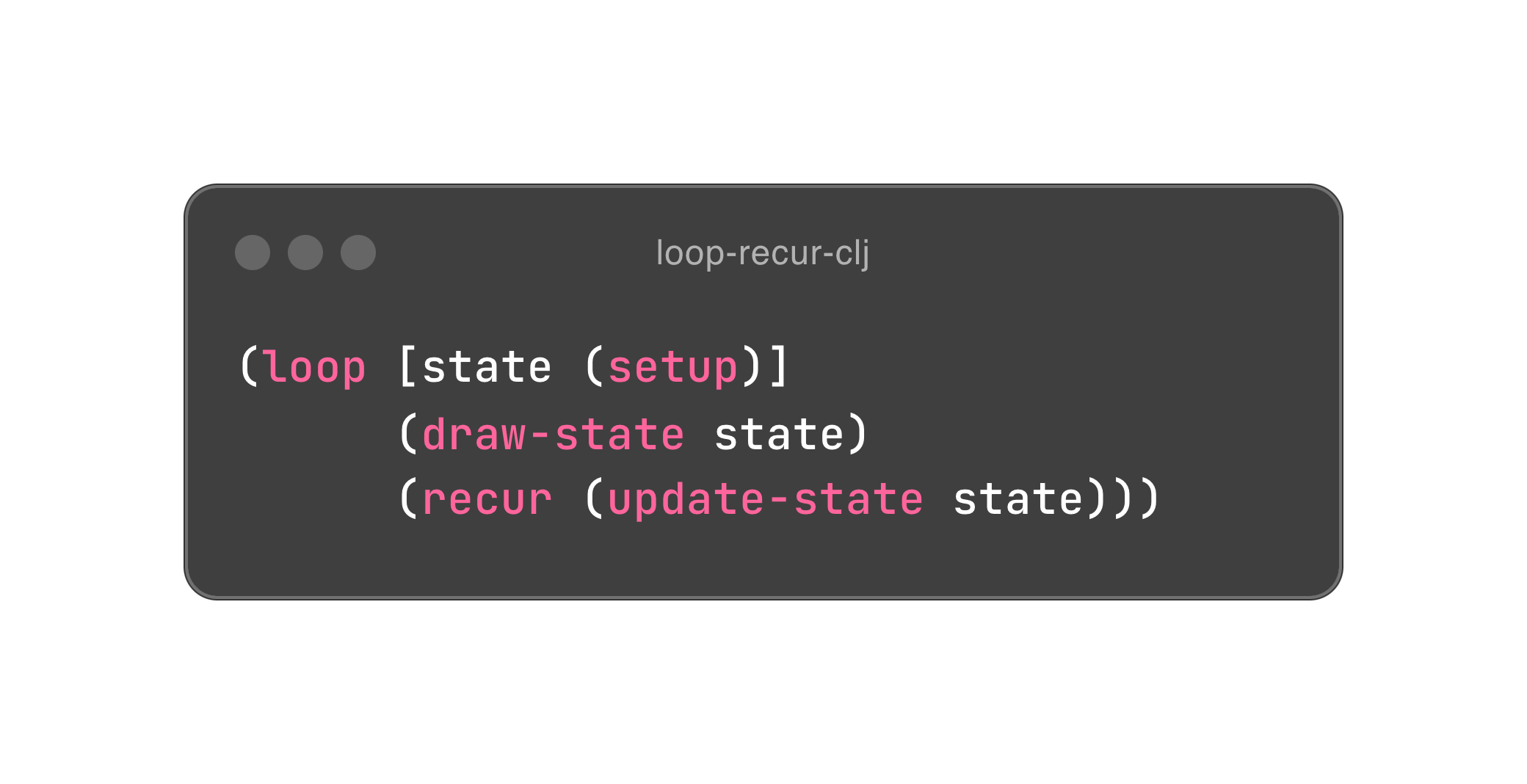
那么到底该怎么做呢?函数式编程中有两大武器,可以实现以旧换新的便宜操作。第一件是递归函数调用(recursive function call),第二件是持久性数据(persistent data)。我们知道,递归函数调用如果未到达递归出口(一般是 if 条件),那么它的栈桢就会不断累积下去,每一层栈桢都可以看作是一次以旧换新;而持久性数据是一种支持多版本的数据结构,它会尽可能地共享数据结构来避免以旧换新时数据的完全拷贝,毕竟,完全拷贝听上去就很浪费。
Two millionaires wish to know who is richer; however, they do not want to find out inadvertently any additional information about each other’s weath. How can they carry out such a conversation?
假如有两位富翁想知道他俩谁更有钱,但是又不愿意暴露自己有多少钱,那么是否存在一种沟通方式完成这件事呢?这个问题就是著名的姚的百万富翁问题。1982年,在加州伯克利分校任教的姚期智发布了一篇题为《安全计算的协议》(Protocols for Secure Computations)论文[1],不仅解决了这个问题,同时还开创了密码学的崭新领域,多方安全计算(Secure Multiple-Party Computation),简称为 MPC 或 SMC。
两位富翁分别叫 Alice 和 Bob,Alice 有 i 百万元,Bob 有 j 百万元,假设 A 和 B 的资产都在一百万到一千万之间,也就是 0 < i, j < 10。
要解决这个问题,我们可以用一个名为带锁的建议箱的隐喻。富翁 Alice 有10只带锁的箱子并且她有一枚解锁的钥匙,并且 Bob 没有钥匙。Alice 将箱子从左到右依次排列。假设她有 6 百万财富值,即 i = 6,于是她从左往右数到第 6 号箱子,并且往第 6 号箱子之前的所有箱子,即 1-5 号箱子,放入标记为 0 的纸条,从第 6 号开始放入标记为 1 的纸条。然后全部上锁离开。这时,Bob 过来看箱子,由于他没有钥匙,所以对箱子中的纸条上的信息一无所知。假设他有 4 百万财富值,即 j = 5,他唯一能做的就是从左往右数到第 4 号箱子,同时将剩下的 9 只箱子全部焚毁。接下来,他将这只箱子交给 Alice,因为 Alice 有钥匙,所以她可以打开箱子。打开箱子后有两种纸条,相应地对应着两种结果。如果纸条是 0 ,那说明 Alice 比 Bob 有钱。反之,若纸条是 1,那说明 Bob 要么比 Alice 有钱,要么和 Alice 一样有钱。在我们的假设中,Alice 打开箱子之后,纸条上标记的是 0,所以 Alice 比 Bob 有钱,而事实确实如此,因为 Alice 有 6 百万元,而 Bob 只有 4 百万元。通过使用这种方法,Alice 和 Bob 除了获得谁更有钱的信息之外,都不知道对方财富值。这种让两方或者多方在保证输入私密的情况下计算某个函数的方法被称为多方安全计算。
当然,我们稍微花费点心思不难发现这个例子中存在泄露秘密的风险。如果 Alice 放入箱子中的是标记 1 - 10 的纸条,那么 Bob 的资产数量就被 Alice 知晓了。这是 MPC 研究的 honest 问题,暂不讨论。
实际中,这个解法具体是怎么工作的?在密码学中,钥匙和带锁的建议箱对应就是非对称密码学体系。Alice 有钥匙,即 Alice 拥有私钥。
对于 Bob 来说,他没有私钥,但是可以使用公钥,他进行下列计算 Bob 选择一个大数 x,并且加密 E(x) = k。 计算 k-j+1 = m,其中 j 是 Bob 的资产 Bob 公开 m 给 Alice,并且告知 m 包含自己的财富值
对于 Alice 来说,她有私钥,需要进行下列计算 计算 m, m+1, m+2, m+3, …, m+j-1=k, …, m+9 也即计算 k-j+1, k-j+2, k-j+3, …, k-j+j, …, k-j+10 使用私钥解密 y[u] = D(k-j+u), 有 y[j] = D(k) = x 求模 z[u] = y[u] mod P,P是质数 z[i] 之前的 z[u] 不变,之后的 z[u] 都+1 Alice 公开所有的 z[u] 给 Bob
Bob 进行检验 若 x mod P = z[j],那么说明没有进行+1的操作,j <= i 若 x mod P != z[j],那么说明进行了+1的操作,j > i
社会主义百万富翁问题[2]
两位员工,名叫 Alice 和 Bob。他们做着同样水平的工作,但是怀疑老板优待他们其中一位,所以想知道自己的薪水是否公平。他们不想暴露自己的工资,也不信任第三方机构,那么他们该如何知道自己是否被公平地对待呢?
假设 Alice 和 bob 的薪水在 10, 20, 30, 40 时薪范围内。我们假设 Alice 的时薪是 30 元,Bob 则是 20 元。我们依然使用带锁建议箱的隐喻打比方。
实际上,这个解法在密码学中被称为不经意传输(Oblivious Transfer,简称 OT)。Bob 给 Alice 发送了多条关于自己时薪是多少的信息,但是 Bob 只能打开那条和自己时薪相关的信息。与此同时,Bob 并没有意识到(Oblivious) Alice 到底想要哪条信息。更一般的定义,不经意传输是一种密码学协议,发送者传输多条消息给接收方,其中只有一条是潜在的消息,但是发送者没法知晓传达到的是哪条消息。不经意传输是由 Maichael O. Robin 在 1981 年首次提出来的。
我们在电影中经常看到这样的场景,若想要开启银行保险柜,需要几个人同时按下指纹。这里所有指纹组成一把开门的钥匙,而每个指纹就是这把钥匙的分片,我们把这种手段叫做密钥分割,秘密分享就可以实现密钥分割。秘密分享简单定义:一个 (t, n) 的秘密分享协议可以将秘密值 s 分成 n 个份额,通过任意 t 个秘密份额都可以完整重建出秘密值 s。少于 t 个秘密份额都无法得到和 s 相关的任何信息。前面提到的银行的例子中 t 就等于 n。秘密分享是 Adi Shamir(RSA 中的 S ) 和 George Blakley 于 1979 年独立发明出来的。
其实,秘密分享完成了多方安全计算的一部分重要的工作,即保证输入的隐秘性。也就是说,Alice 可以将自己的输入参数以秘密分享的方式分享给 Bob,此时 Bob 只是拿到了 Alice 输入参数的一个份额并不知道原始输入是什么。同理,Bob 也可以将自己的输入一秘密分享的方式公布给 Alice。如果想要完成安全计算,那么还剩下一个问题:如何将这些份额组合起来并运行一个函数,最终得出结果。
加法门
以加法为例。假设 Alice 的隐私输入是 5,Bob 的隐私输入是 8,我们首先将 5 和 8 分别进行秘密分享。为了方便计算,我们将直线的斜率都设为 -1。也就是说,Alice 的直线为 y=5-x, Bob 的直线为 y=8-x,因此只需要分别给出两处纵坐标即可。即 Alice 的秘密值 5 可以分成 (2, 3) 和 (3, 2) 简写成纵坐标 3 和 2,而 Bob 的秘密值 8 可以分成 9 和 -1。然后他们之间交换份额,得到: Alice:a[0] = 3, b[0] = 9 Bob:a[1] = 2, b[1] = -1 此时,Alice 拥有了 Bob 的份额 b[0]=9,Bob 也有了 Alice 的份额 a[1]=2。
asyncdefbeaver_multiply(ctx, x: Share, y: Share): """The hello world of MPC: beaver multiplication Linear operations on Share objects are easy Shares of random values are available from preprocessing Opening a Share returns a GFElementFuture """ s, t, st = ctx.preproc.get_triples(ctx) Alpha = await (x - s).open() Beta = await (y - t).open() # Alpha*Beta is multiplying GFElements # Alpha*t, Beta*s are multiplying GFElement x Share -> Share # st is a Share # overall the sum is a Share xy = (Alpha * Beta) + (Alpha * t) + (Beta * s) + st return xy
调用的代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
x = ctx.Share(5) + ctx.preproc.get_zero(ctx) y = ctx.Share(7) + ctx.preproc.get_zero(ctx)
xy = await beaver_multiply(ctx, x, y)
# Check openings of the multiplied values
X = await x.open()
Y = await y.open()
XY = await xy.open()
assert XY == X * Y
print(f"[{ctx.myid}] Beaver Multiplication OK")
beaver_multiply 函数中进行了封装,我们可以拆解还原计算过程。 s, t, st = ctx.preproc.get_triples(ctx) 这里就是获取 s, t 和 st 的步骤,代码中省略了初始化三元组的过程。 Alpha = await (x - s).open() 对应上面说到的算式
如果从软件的规模这个角度来考察这个定义,我们就会发现软件可以无限庞大下去。基于这样的假设,我们可以推论出软件并不是一种物理现象。1972年,荷兰计算机科学家迪杰斯特拉(Edsger W. Dijkstra)将软件描述为“分层系统”,因为我们需要用分层来解释和实现我们所构造的现象,而不是经由物理规律来考验这些现象。所以 SICP 一书中将软件称为“程序认知论”(阿贝尔森和萨斯曼)就非常有道理了。
软件工程师常常把分层系统看做是解决某些复杂软件问题的良药,然而事实上,软件其实就是分层系统,基于 OSI(Open System Interconnection) 模型的技术栈就是一种典型的例子。在 OSI 出现之前,曾经有项目尝试适配各种主机以完成各种异构网络之间的联通,但是均以失败告终。而 OSI 引领的标准让世界各地的工程师们协作起来逐步推进了网络技术栈的发展。现如今,我们操作图片时,已经完全无法想象它和比特之间的关联,因为它们已经相差得太远了。远到我们无需考虑有比特这么回事,更不用说底层的半导体控制的电流开关。
因此,我们不得不提到另一个安迪-比尔定律。这个定律的原话是安迪所给的,比尔全都拿走。其中的安迪就是今天全球最大的个人计算机零件和CPU制造商英特尔公司的创始人兼当时的 CEO 安迪·格鲁夫,而比尔就是比尔盖茨。这条定律的意思是微软等软件公司的新软件总是比从前的软件更加耗费资源,以至于完全抵消了英特尔等硬件公司带来的性能提升。我们的切身体验也是,你拿着老旧的手机去运行现在的软件会感觉慢得不要不要的。
大概就是在这种契机下,我开始学习 Rust 的。依照老规矩,我还是会从 tree 这个命令行程序入手,在试错中逐步学习 Rust 这门语言。包含它的基本数据类型,组合数据类型,控制流,模块(函数)以及文件和集合操作,还有最关键的 Ownership 的应用。
实践出真知
学习 Rust 最深刻的体验莫过于和编译器较劲,这也是我听到过最多的抱怨。我想许多新手看到这么多警告或者错误,嘴上不说,心里应该很不是滋味。但是这也是 Rust 引以为豪的设计哲学,每一门新进的语言都有自己的本质原因(Rationale)或者设计哲学,比如 Lisp 家族的 Clojure 就有 Elegance and familiarity are orthogonal 的玄言妙语;往远古追溯,Java 的 Write Once, Run Anywhere 豪言壮语;而 Rust 的基本设计哲学是 If it compiles, then it works,这个条件有多苛刻我们稍微想一想就能知道——动态弱类型语言向静态强类型语言的逐步趋同态势,基本已经宣告了类型系统的胜利,但即便如此,现代软件工程也还是处处强调程序员要手写各种测试确保代码运行时的正确性——从单元测试到集成测试,从冒烟测试到回归测试,从 Profiling 到性能测试。这些测试方法和工具已经深入到软件工程的方方面面,然而各类软件还是漏洞百出。Rust 发出这种高调宣言,不免有夜郎自大之嫌疑。不过程序届是个能造概念也能落地概念的神奇圈子,高调的牛吹着吹着也就实现了。况且,Rust 充分诠释了现代编程语言的核心思想——约束程序员,不是劝劝你的意思,是憋死你的意思。
我在《我是如何学习新的编程语言》中说过学习的最好方式是有目的地试错,我时常拿来练手的程序叫tree - list contents of directories in a tree-like format. 这段程序需要用到的 Rust 基本构件有:
let v = vec![1, 2, 3]; v.extend([1, 2, 3].iter().cloned()); // 编译错误
注意,这里编译失败。Rust 编译器会直截了当地给出错误信息。
1 2 3 4 5 6 7
error[E0596]: cannot borrow `v` as mutable, as it is not declared as mutable --> src/main.rs:13:5 | 12 | let v = vec![1, 2, 3]; | - help: consider changing this to be mutable: `mut v` 13 | v.extend([1, 2, 3].iter().cloned()); | ^ cannot borrow as mutable
let mut v = vec![1, 2, 3]; let r1 = &mut v; let r2 = &mut v; assert_eq!(r1, r2);
编译器会立即给出编译错误
1 2 3 4 5 6 7 8 9
error[E0499]: cannot borrow `v` as mutable more than once at a time --> src/main.rs:13:10 | 12 | let r1 = &mut v; | ------ first mutable borrow occurs here 13 | let r2 = &mut v; | ^^^^^^ second mutable borrow occurs here 14 | assert_eq!(r1, r2); | ------------------- first borrow later used here
fn render_tree(tree: &Entry) -> Vec<String> { let mut names = vec![tree.name]; // error let children = &tree.children; let children: Vec<_> = children .iter() .enumerate() .map(|(i, child)| decorate(children.len() - 1 == i, render_tree(child))) .flatten() .collect(); names.extend(children);
names }
这里会有编译错误,错误信息如下:
1 2 3 4 5
error[e0507]: cannot move out of `tree.name` which is behind a shared reference --> src/main.rs:48:26 | 48 | let mut names = vec![tree.name]; | ^^^^^^^^^ move occurs because `tree.name` has type `std::string::string`, which does not implement the `copy` trait
59 | names | ^^^^^ expected struct `std::string::String`, found reference | = note: expected type `std::vec::Vec<std::string::String>` found type `std::vec::Vec<&std::string::String>`
embark run会启动一个命令行中可视化界面,里面会告诉你当前Dapp的状态,包括智能合约是否部署,哪些组件服务可用,最最重要的是它会告诉你接下来你该做什么!在Logs视窗中,embark试图告诉你开发环境确实哪些依赖服务,比如geth节点没有启动(事实上,可以用gananche-cli代替),ipfs节点未侦测到,Cockpit Web UI所在端口还有Dapp服务的入口等等。而console视窗则是命令交互入口,一条help命令就能展示很多有用信息。
constructor() public { balances[msg.sender] = 10001; }
function sendCoin(address receiver, uint amount) public returns(bool sufficient) { if (balances[msg.sender] < amount) return false; balances[msg.sender] -= amount; balances[receiver] += amount; emit Transfer(msg.sender, receiver, amount); return true; }
function getBalanceInEth(address addr) public view returns(uint) { return ConvertLib.convert(getBalance(addr), 4); }
function getBalance(address addr) public view returns(uint) { return balances[addr]; } }
当把这两个智能合约文件放到项目根目录下contracts/目录中后,合约代码被自动编译,并在Contracts视窗中展示出来,状态为Deployed,这表明智能合约已经被部署到区块链网络里。之后,我进入Cockpit Web UI,惊喜地发现这个服务俨然就是一个高配版的etherscan.io,通过它不仅可以查看部署之后的合约,甚至还可以调用合约方法。
generateMnemonic(...)函数的参数rng全称是random number generator,即随机数发生器,默认是randomBytes。此处,ENT的默认长度是128位,运行randomBytes(128/8)将产生了16字节的随机数。然后调用entropyToMnemonic(...)函数生成助记词。
// 128 <= ENT <= 256 if (entropy.length < 16) thrownewTypeError(INVALID_ENTROPY) if (entropy.length > 32) thrownewTypeError(INVALID_ENTROPY) if (entropy.length % 4 !== 0) thrownewTypeError(INVALID_ENTROPY)
var entropyBits = bytesToBinary([].slice.call(entropy)) var checksumBits = deriveChecksumBits(entropy)
var bits = entropyBits + checksumBits var chunks = bits.match(/(.{1,11})/g) var words = chunks.map(function (binary) { var index = binaryToByte(binary) return wordlist[index] })
function mnemonicToSeed (mnemonic, password) { var mnemonicBuffer = Buffer.from(unorm.nfkd(mnemonic), 'utf8') var saltBuffer = Buffer.from(salt(unorm.nfkd(password)), 'utf8')
var data = Buffer.concat([this.publicKey, indexBuffer]) var I = crypto.createHmac('sha512', this.chainCode).update(data).digest() varIL = I.slice(0, 32) varIR = I.slice(32)
var hd = newHDKey(this.versions) // Private parent key -> private child key // ki = parse256(IL) + kpar (mod n) hd.privateKey = secp256k1.privateKeyTweakAdd(this.privateKey, IL)
exports.privateKeyTweakAdd = function (privateKey, tweak) { var bn = BN.fromBuffer(tweak) if (bn.isOverflow()) thrownewError(messages.EC_PRIVATE_KEY_TWEAK_ADD_FAIL)
bn.iadd(BN.fromBuffer(privateKey)) if (bn.isOverflow()) bn.isub(BN.n) if (bn.isZero()) thrownewError(messages.EC_PRIVATE_KEY_TWEAK_ADD_FAIL)
One weakness that may not be immediately obvious, is that knowledge of a parent extended public key plus any non-hardened private key descending from it is equivalent to knowing the parent extended private key (and thus every private and public key descending from it). This means that extended public keys must be treated more carefully than regular public keys. It is also the reason for the existence of hardened keys, and why they are used for the account level in the tree. This way, a leak of account-specific (or below) private key never risks compromising the master or other accounts.
代码解释
继续使用hdkey[^1]来解释
1 2 3 4 5 6
let hdWallet = hdkey.fromMasterSeed(seed) let key = hdWallet.derivePath("m/44'/60'/0'/0/0") console.log("publicKey:", key1._hdkey._publicKey.toString("hex"), "\nextendPublicKey:", key1.publicExtendedKey()) -> publicKey: 03795fd38bbffdddb24b72af417cf3fa540db8f60783dd32f61f0ca5af464fd492 extendPublicKey: xpub6GmbjntbdLF4JNhBxwoRBrdw2BBujvJ514tRHFMQaoFA5eSRaWwr6CQSGq1HtirLGSTT8SHqMGWQk4rbZLJsVFA4NLZZYUR25ZEdhnGJ7R1
let privateKeyBuffer = Buffer.from(privateKey, "hex") // or "base64" let publicKey = secp256k1.publicKeyCreate(privateKeyBuffer, false).slice(1); let address = "0x" + keccak256(publicKey).slice(-20).toString("hex");
let privateKeyBuffer = Buffer.from(privateKey); let publicKey = secp256k1.publicKeyCreate(privateKeyBuffer, false).slice(1); let address = "0x" + keccak256(publicKey).slice(-20).toString("hex");
 {:height 442, :width 780}
{:height 442, :width 780}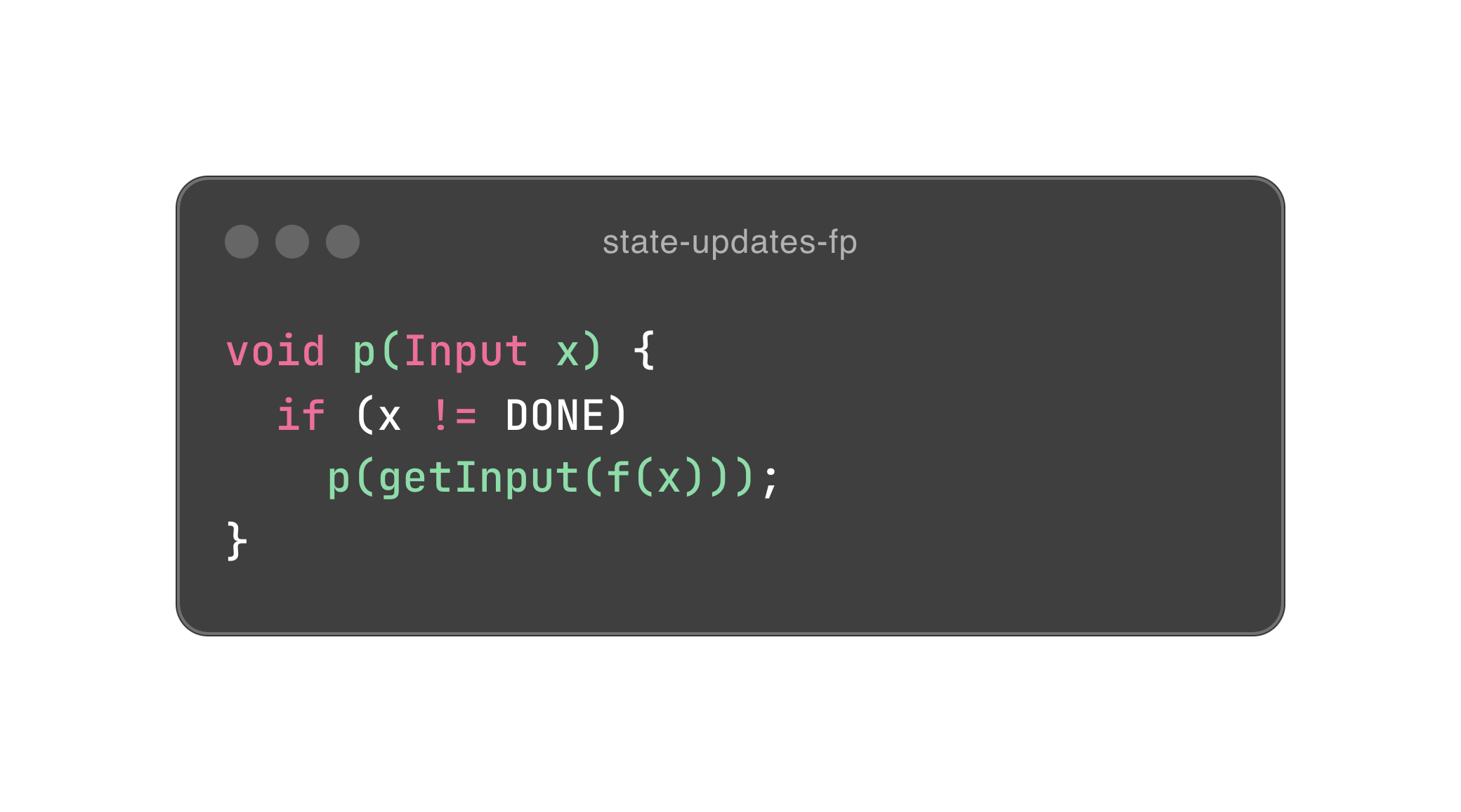





 {:height 437, :width 476}
{:height 437, :width 476}